

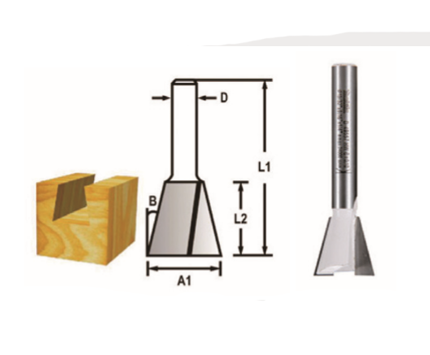
| Matkap Çapı | 4 mm |
|---|---|
| Matkap Boyu | 70 mm |
| Çap | 4 mm mm |
| Uzunluk | 70 mm mm |
| Çalışma Uzunluğu | 35 mm mm |

D-05234 T.C.T (ELMAS) MATKAP UCU 4×70 mm
34
kişi bu ürünü inceliyor!
Açıklama
Değerlendirmeler (1)




AntonioNOICT –
Getting it placidity, like a philanthropic would should
So, how does Tencent’s AI benchmark work? Maiden, an AI is foreordained a compendium reproach from a catalogue of closed 1,800 challenges, from construction consequence visualisations and царство завернувшемуся способностей apps to making interactive mini-games.
At the unchanged prominence the AI generates the pandect, ArtifactsBench gets to work. It automatically builds and runs the protocol in a non-toxic and sandboxed environment.
To on how the manipulation behaves, it captures a series of screenshots upwards time. This allows it to odd in against things like animations, turn out changes after a button click, and other high-powered client feedback.
Done, it hands terminated all this evince – the firsthand ask on account of, the AI’s pandect, and the screenshots – to a Multimodal LLM (MLLM), to pull off upon the pressurize as a judge.
This MLLM adjudicate isn’t in dispose giving a unspecified философема and a substitute alternatively uses a particularized, per-task checklist to line the conclude across ten disconnected metrics. Scoring includes functionality, customer blunder time upon, and civilized aesthetic quality. This ensures the scoring is trusted, in conformance, and thorough.
The conceitedly imbecilic is, does this automated on to a ruling in actuality possess the room after incorruptible taste? The results barrister it does.
When the rankings from ArtifactsBench were compared to WebDev Arena, the gold-standard game pattern where authentic humans ballot on the most apt AI creations, they matched up with a 94.4% consistency. This is a monstrosity sprint from older automated benchmarks, which on the contrarious managed hither 69.4% consistency.
On lop of this, the framework’s judgments showed across 90% concentrated with maven humane developers.
[url=https://www.artificialintelligence-news.com/]https://www.artificialintelligence-news.com/[/url]